Cette semaine, Codergo était à Paris, invité par Google en qualité de GDE (Google Developer Expert – spécialité Google Workspace) pour participer à une session de 3 jours. Je remercie au passage Google de m’avoir invité et de m’avoir permis d’assister à cette série d’évènements. Ceci est la troisième journée.
L’annonce : Gemma3
La matinée a commencé en grande pompe avec l’annonce officielle de la disponibilité de Gemma3 !
Tris Warkentin, Director, Product Management at Google Deepmind, nous a présenté le nouveau venu et ses qualités.
Voici la liste de ses qualités !
- Gemma3 est performant : il est disponible en 1B, 4B, 12B et 27B. Pour rappel, B est pour “billion” soit “milliard de paramètres” en français.
- Gemma3 est multilingue : il est utilisable en plus de 140 langues.
- Gemma3 est multimodal : c’est-à-dire qu’il supporte plusieurs formats en entrée. En particulier : toutes les résolutions d’image, efficace même sans post-training, focalisé sur les instructions seulement, et accepte plusieurs entrées successives. Par exemple, on peut lui fournir une image et lui poser des questions successives sur cette même image.
- Gemma3 propose une grande fenêtre contextuelle : 128k tokens, contre 8k tokens précédemment.
- Gemma3 est 2eme au classement Chatbot Arena Elo Score des plateformes ouvertes, qui est une référence en matière d’évaluation des niveaux de compétence relatifs des LLMs.
- Gemma3 est 9eme au classement Lmsys Chatbot Arena, toutes plateformes confondues.
- Gemma3 est compatible avec de nombreux éditeurs de code, comme Hugging Face Transformers, JAX, Keras, Ollama, PyTorch, Mediapipe, vLLM, et d’autres.
Par ailleurs, Gemma3 se décline comme Gemini 2.0 sur plusieurs modèles, relatifs à leur nombre de paramètres:
- 1B : modèle de texte léger, idéal pour les petites appplications
- 4B : équilibré pour la performance et la flexibilité, avec de la multimodalité
- 12B : forte capacité de langage, conçu pour des tâches complexes
- 27B : compréhension améliorée, parfait pour des applications sophistiquées
Enfin, les ingénieurs de recherche Google Deepmind se sont succédés pour nous présenter un aperçu de leurs travaux.
Voici les grandes lignes de ce que j’ai retenu.
Prompts
Nous avons eu également quelques indications pour les prompts à utiliser avec Gemma3, pour les développeurs :
- être concis : “réponds par oui ou non”
- fournir des instructions du système à utiliser dans l’invite de l’utilisateur : “implémente une fonction JAX qui fait…”
- s’appuyer sur les capacités d’interactions en plusieurs tours
Agent AI
Cette notion a été introduite par Kathleen Kenealy, Staff Research Engineer at Google Deepmind, en réponse à une tendance qui tend à populariser ce terme.
On désigne ainsi la possibilité de converser avec l’outil, et de lui déléguer la façon dont il traite l’information fournie en entrée pour nous restituer sa réponse. C’est en quelque sorte ce qui deviendra un assistant au sens où on l’entend généralement.
Pour illustrer, si vous commandez un burger dans un restaurant, vous ne précisez pas comment le préparer, les outils pour le cuire, etc. C’est la même chose pour la notion d’Agent AI, vous ne lui indiquez pas comment il doit fonctionner pour répondre à vos besoins.
Par opposition à un modèle IA, auquel vous ne déléguez rien mais indiquez vos instructions : résumer un article ou générer du code par exemple.
Entraînement d’un modèle, l’envers du décor
Nous avons eu la chance d’avoir des explications techniques sur la phase d’entraînement des modèles.
De très nombreuses techniques co-existent, qui sont un savant mélange d’ingestion de données, de calculs probabilistes, et de correction de biais d’entraînement.
Il y a deux phases principales pour la construction d’un modèle :
- le pre-training : pré-entraînement
- le post-training : “post-entraînement”, également appelé “fine-tuning”, ou ajustement
Le pre-training est constitué de l’ingestion d’une grande masse d’informations, avec une première phase de réglage. Cette phase implique un travail sur la qualité des données à ingérer : Internet contient de plus en plus de données de qualité discutable, les sources premières d’informations sont privilégiées.
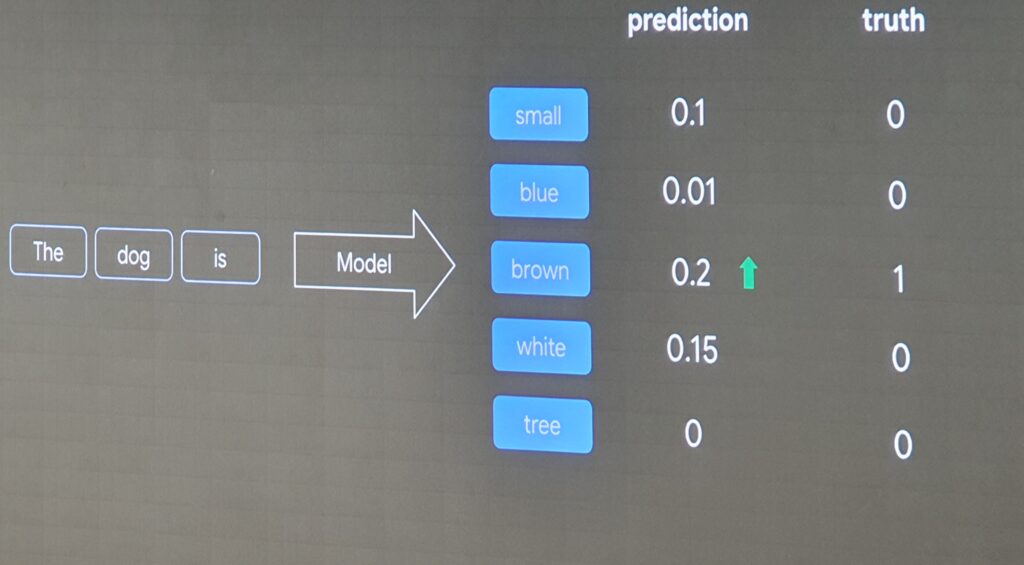
Le post-training est constitué de la mise en contexte et vérification, manuelle ou mathématique, des résultats émis par le modèle.
Une des raisons du fine-tuning est d’être le plus adapté possible à un cas d’usage : médical, mathématique, et programmation par exemple.
Plusieurs méthodes de fine-tuning coexistent :
- RAG : Retrieval Augmented Generation : recherche d’informations dans une base de données ou sur internet pour apporter une réponse précise
- LoRA : Low-Rank Adaptation, ou “Distillation” : méthode d’allègement des calculs dans la réponse
- et plein d’autres encore, je n’ai pas tout noté !
La phase de requête
Lors d’une requête, l’objet de cette requête est traduit en “input token”, qui sont les unités de comptage dans le secteur. Ceux-ci sont ce qu’on appelle la “fenêtre contextuelle”, c’est en quelque sorte la mémoire courte de la requête.
La phrase est ensuite interprétée, segmentée, traduite en vecteurs de calcul, puis confrontée à un modèle de calcul. Le résultat est exprimé aussi sous forme de “output token”.
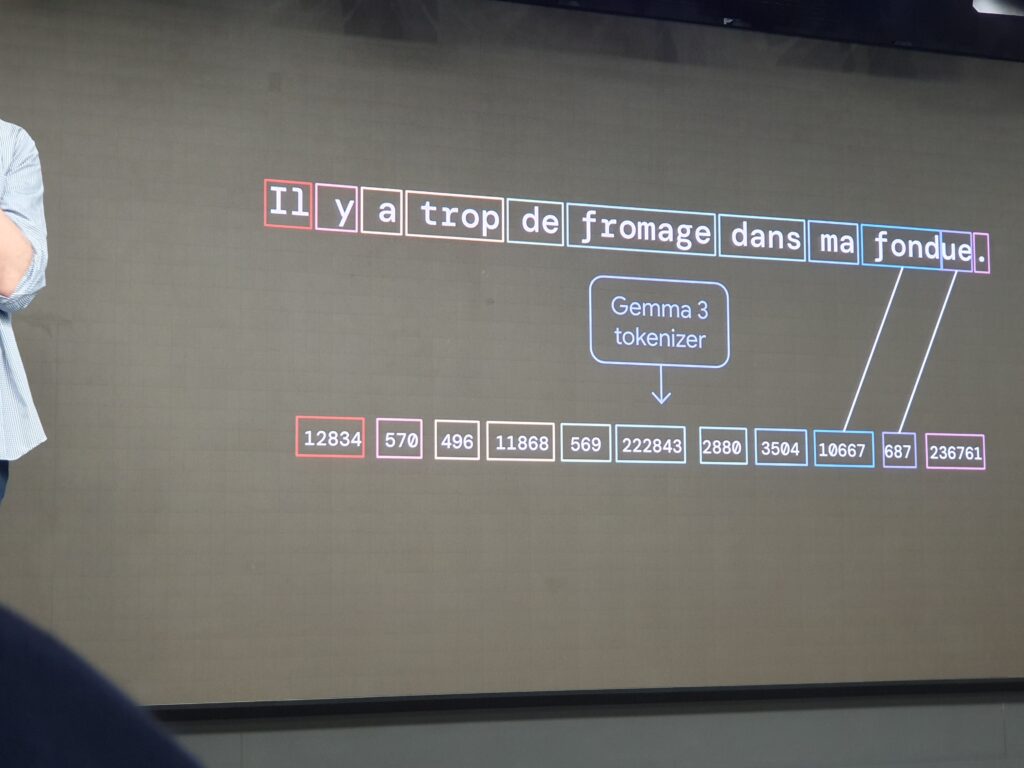
Il est à noter que l’entraînement se poursuit pour lutter contre les biais d’influence du modèle. La phrase importante : “the truth is not the best answer”. Si la probabilité indique une réponse, elle n’en est pas moins une probabilité et non la vérité absolue.

Pour en savoir davantage : ai.google.dev/gemma
SynthID : filigraner une production IA
c’est la technique développée par Google pour filigraner les éléments produits, que ce soit sur du texte, une image ou une vidéo, et pouvoir par la suite identifier si l’objet trouvé est issu d’une IA. Il y a bien sûr une notion de propriété intellectuelle.
Cette méthode est en open-source ! Plus d’informations disponibles ici.
LeRobot
Nous avons eu une démo d’un robot qui réagit et fonctionne avec de l’IA !

Prototype fort sympathique au demeurant, capable de reproduire des tâches domestiques par exemple.
Sur le stand de démo, à partir d’une simple caméra, un bras de robot entraîné reproduisait le mouvement d’un autre bras manipulé par les utilisateurs. Impressionnant !
POur en savoir plus : github.com/huggingface/lerobot
La famille de Gemma : Gemmaverse
Il y a plus de 60 000 modèles et déclinaisons de Gemma produits en un an :
Gemma, CodeGemma, RecurrentGemma, ShieldGemma, PaliGemma, Gemma2, GemmaScope, PaliGemma2, DataGemma, ShieldGemma2, Gemma3…
Et ceci, sans compter les catégories :
Ko-gemma, Gemmax, SILMA Kashif, Lumina Image, OmniAudio, SimPO.
Il faut bien comprendre que chaque modèle est puissant, mais que certains sont spécialement entraînés pour des cas d’usage spécifiques.
Si vous voulez en utiliser un, il est pertinent de prendre le plus adapté pour l’adapter à votre situation.
Aparté : IA et LLM, une histoire de probabilité
L’Intelligence Artificielle, plus précisément désignée sous le terme de LLM (Large Language Model) est avant tout une histoire de probabilités. Il est souvent dit que l’IA n’a pas de conscience, et les Googlers insistent bien dessus.
Il s’agit d’entraîner un moteur à fournir une série de mots selon un degré de probabilité dépendant d’un prompt qui fournit un contexte.
Malgré tout, l’usage de termes humanisants tels que “hallucinations” lorsque la réponse n’est pas correcte ou à côté de celle attendue, serait idéalement à proscrire pour lui préférer les termes “erreur de contexte”, “erreur d’entraînement”, ou “réponse aléatoire”.
Aparté : écologie
Un élément qui n’a pas été mentionné est le coût écologique de l’IA, ce qui à titre personnel m’intéresse également.
On le sait, l’IA est très gourmande en ressources énergétiques. Le progrès a un coût bien sûr, qu’on le veuille ou non. Il convient aux propriétaires des infrastructures d’avoir les outils de calcul les plus efficaces possibles en anticipation d’un effet rebond. Il convient également aux utilisateurs de s’en servir à bon escient, et aux politiques de mettre en place des garde-fous sur leur usage.
A titre de culture générale, vous pouvez lire ici le rapport d’intermédiaire du Shift Project sur l’IA, les données, les calculs.
Quelques ordres de grandeur ci-dessous issus de ce rapport intermédiaire. Un grand merci à Michael Ravier pour m’avoir partagé ces quelques chiffres !
- 30% de l’électricité consommée en Irlande l’est pas des centres de données.
- Faire 10 prompts par jour en moyenne sur Chat GPT émettrait à la louche 100 kg de CO2 par an. Soit environ 800 km de trajet en voiture.
- Google et Microsoft ne communiquent pas sur l’impact de leurs IA, mais leurs émissions Groupe ont augmenté de 50% en 3 ans. De façon générale, beaucoup de données manquantes de la part d’acteurs clés (NVidia notamment).
En conclusion
Cette semaine a vu s’enchaîner une série d’annonces, de présentations, d’explications, de démonstrations bluffantes. Parfois très accessibles, parfois très techniques.
Une chose est certaine, l’IA fera partie de notre quotidien avec une intensité croissante !